
The latest buzzword in prediction and analytics is a small but appreciated incremental improvement.
As AutoML reaches the analytics hype cycle peak expect to see the term flung around more often. This article will describe what AutoML does and doesn’t do, and if it’s any good.
The data science profession is a frequent target of vocational annihilation, year after year new products are marketed to finally replace the data scientists, with corresponding articles heralding their demise (here and here). So when a tool called auto + [insert buzzword here] starts appearing in analytics product offerings I see it as another chapter in the short history of automated machine learning where “tools … to eliminate the need for expert analysts …that alienate the few people in organizations who understood the product well enough to serve as champions.” Despite how it’s positioned in the market, I demonstrate below that AutoML is essentially a tool for data scientists, that far from replacing them, liberates them to focus on other or higher value business problems – ironically embedding their position within the organisation.
Most of the platform vendors are offering an AutoML capability, a few of them are listed below.
So what do these products do?
To set the context, back in the old days of data science a lot of time was consumed to conform data to fit into rigid machine learning algorithms:
- Centering and scaling
- One-hot encoding
- Imputing missing data
- Binning data
These sorts of tasks are long since abstracted into the machine learning algorithms themselves, in that sense automated ML has been around a while. It is the next two steps that AutoML proposes to simplify; model choice and hyper parameter selection. There are a few models to choose from, neural nets, boosters, forrests – each one of these has it’s own set of parameters e.g. layer topology, learning rate, tree size – and a lot, lot more. AutoML will choose the model and the best parameters for that model. It should be pointed out that hyper parameter optimisation has long since been carried by a technique called grid search. AutoML proposes to abstract this into a general algorithm that runs a hyper-parameter grid search on each machine learning algorithm.
AutoML will choose the model and the best parameters for that model.
If you think something like this may take a long time to run, you’d be right. It has even spawned a new term; hyper-hyper-parameter selection. Despite the name, these parameters represent the less abstract concepts:
- Model building time – Set the maximum amount of time that AutoML has to build the model. An appropriate choice may be the number of hours passed between leaving the office in the evening, and arriving the following morning.
- Computational resources – CPU cores and RAM. A good choice is everything that’s available.
- Ranking metric – What method is used to sort the best from the rest? This depends on the statistical attributes of the target variable and how the model is to be used. This should be carefully chosen and explained to stakeholders. Typical metrics include RMSE, R2, AUC, F1.
But there are ultimate time savings associated with model building that make AutoML a useful tool.
A more subtle question to ask is: What if the model is so important that small changes in accuracy correspond to millions of dollars? For example – fraud detection. When the stakes are high AutoML won’t deliver the best model per buck – in this case a dedicated team with bespoke models is the more sensible approach. But for low-medium value, low-medium risk applications this tool will find a home.
What AutoML does not do
Despite the name, AutoML won’t be a tool for subject matter experts and BI professionals to carry out data science, it automates a small part of the model building, which itself is typically (but not always) a small part of what a data scientist does. Although a little dated, the old CRISP-DM diagram below representing the data mining process illustrates where a tool like AutoML fits into a broader process:
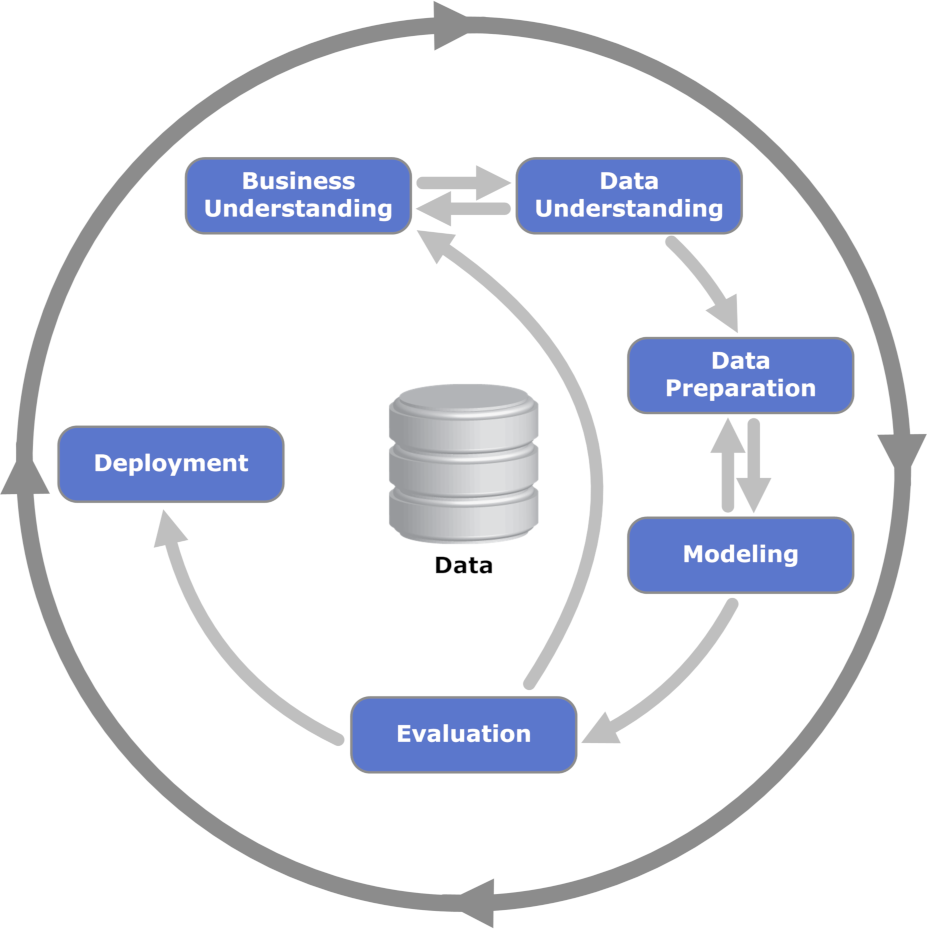
AutoML assists the modelling and data preparation components, it does not impact any other part of the process.
How good is it?
In recent articles I iteratively improved a weather prediction model by developing and adding new data and features. I maintained the same model and hyper-parameters throughout, and evaluated the change in accuracy associated with adding new data. Let’s flip this. Holding the given data constant, AutoML will seek the best model and hyper-parameters that increases model accuracy. The following table is the root mean squared error associated with a day-ahead max temperature prediction algorithm, we compare AutoML against a stable of ML algorithms in the H2O stable. (Lower RMSE is better)
| Algorithm | RMSE |
|---|---|
| Deep Learning | 3.56 |
| Random Forrest | 3.27 |
| Generalised Linear Model | 3.25 |
| Gradient Boosting | 3.20 |
| XGBoost | 3.12 |
| AutoML | 2.26 |
Using default parameters, AutoML greatly outperforms all other algorithms in the machine learning stable – with essentially no additional effort.
Conclusion
These sorts of tools liberate a little of the precious time of your organisations’ data scientists. It won’t solve any other structural problems with your organisation’s analytics function such as skills shortage, poor data quality, siloed analytics efforts, lack of analytics platform, … AutoML is a nice to have but not a need to have.